
为了能正确使用法线贴图,我们需要在切线空间进行光照,本文记录切线的计算以及 TBN 矩阵的推导,并完善一些细节。最后分别在切线空间、世界空间、观察空间实现 ADS 光照(都实现一遍便于对各个空间有更清晰更深入的理解,并区分其优劣)。
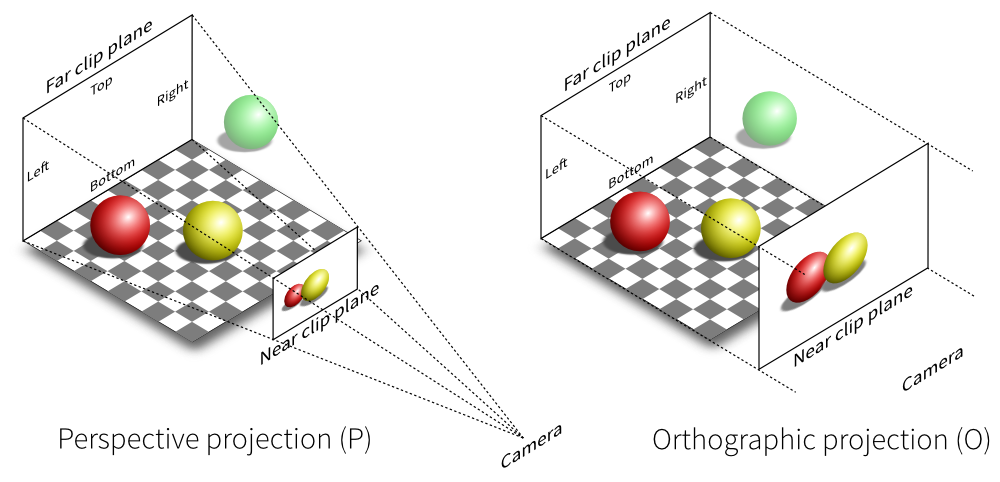
实际在 OpenGL 中的变换的一些记录,尤其是与 「GAMES101」Transformation 推导中的一些区别。其中旋转、平移等常见变换以及视图变换均是相同的。这里主要讨论正交投影和透视投影,以及法线变换矩阵的推导。

Some code and techniques in modern C++(11, 14, 17, 20(just 2a)).
扩展埃拉托色尼筛法可以在大约 $O(n ^ {\frac {2} {3}})$ (这里以实际运行效果估计,实际复杂度据说和洲阁筛一样)求出一般积性函数的前缀和,消耗 $O(\sqrt{n})$ 的空间。
在 OI 中,我们手写的数据结构几乎都是静态内存的,而 STL 中的容器由于内存动态化的原因在做题中容易 TLE,这里介绍几种常见容器静态化内存的方法。
作为一个先学工程的蒟蒻 oier,也就只能在卡常上有一些技巧了……
然而我太弱,并没有去成 WC,虽然感觉 T2 卡三级缓存不是应该很好卡吗?
这里总结松爷的一些技巧和记录一些其他技巧及一些实际例子。
有限状态自动机 DFA,功能就是识别字符串,令一个自动机 $A$,若能识别字符串 $S$,就记为 $A(S) = true$,否则 $A(S) = false$。自动机由五个部分组成,$alpha$ 为字符集,$state$ 状态集合,$init$ 初始状态,$end$ 结束状态集合,$trans$ 状态转移函数。
$tarns(s, ch)$ 表示当前状态是 $s$,在读入后字符 $ch$ 后所到达的状态;同时 $tarns(s, str)$ 表示当前状态是 $s$,在读入后字符串 $str$ 后所到达的状态。
如果 $trans(s, ch)$ 这个转移不存在,我们设其为 null,同时 null 只能转移到 null,null 表示不存在的状态。

![]()
![]()
Update your browser to view this website correctly. Update my browser now